
Helpful vs. Harmful Complexity for Forecasting
Experiments in Scaffolding (AI Forecast Bot Experiment #2)


When building things that use LLMs, like my forecasting bot, there are a handful of levers that can be pulled on to squeeze out better performance. I’ve talked about these in the past, and shared an experiment where I compared model choice for the narrow but important piece of not making things up. This post is another experiment, this time looking at the scaffolding built around the model.
Scaffolding here refers to all the programming structure you place around the LLM itself, and it’s big business. Most AI startups are not trying to build frontier models (which are pushing billion dollar training runs) but instead are using scaffolding to build wrappers of existing models. There are some wildly successful versions of this, like Cursor (worth $29B) or Perplexity (worth $20B). Unless you’re a hyperscaler, scaffolding is how you build your company and set yourself apart.
This is also a big piece of how different people approach the AI forecasting tournament I’m in. Last tournament’s winner Panshul42 open sourced his bot, so you can see the significant scaffolding he’s constructed that includes specialized parallel web searching, synthesis, and aggregation wrapped around the main forecasting model call.
But, despite all this, I have some doubts about how much scaffolding really matters. The pace of progress in LLMs is staggering, and many low-hanging fruit scaffolding improvements just end up wrapped into the core models themselves as time goes by. Especially for an individual working on this bot in your free time, how much ROI can you expect to get by spending a ton of time improving your scaffolding?
Maybe Scaffolding is a Waste of Time?
It’s hard to break free from the intuition that by putting in more work, building more advanced methods and tools to run on top of the LLM, you should get better performance. I mean, people are making billion dollar companies that are fundamentally a fork of VS Code with a pipeline to LLMs built in. But there are good reasons to think this might not apply to forecasting.
The first is that the top 3 performers from the last quarterly tournament were all individuals, while the next 3 were commercial entities. There is plenty of randomness in this kind of tournament (and the prior quarter’s tournament was won by a startup), so this could just be noise. It’s also possible that the incentives of a startup are different from the incentives for individuals. For instance, if you’re running a startup you might be more concerned about developing a cost effective forecaster bot that you fully control while an individual might have more freedom to pick the most effective (and expensive) model.
But scaffolding is a place where companies should have a decisive advantage over individuals. It is often a straightforward software engineering problem, and while individuals can be highly effective your default expectation should be that a team of engineers is going to have an easier time building their ideal architecture than a single person working on this project in their free time. So, if scaffolding provided a significant advantage in building forecasting bots, you should expect that the companies would dominate these tournaments.
The second reason is that even in AI research the improvements from scaffolding don’t seem to be that dramatic. A couple relevant examples in the context of fact checking are the FEWL (2024) and SAFE (2025) architectures, which are very sophisticated scaffoldings aimed at improving factuality. Both of these work, and improve the accuracy of state of the art models. However, in absolute terms I have to say that these improvements are pretty modest. Compared to the base model, FEWL had an improvement of around 8% accuracy, and SAFE ranged from 2-6%. It’s also notable that the older paper, using older models, had more improvement than the newer paper on newer models. As the models get better, it’s harder to squeeze out improvements by attaching things to the outside.
This isn’t to degenerate the importance of this type of scaffolding work. Improving performance above state of the art is extremely challenging, and a few percentage points of improvement is nothing to sneeze at. But it does make me suspicious about the practical value of dedicating a ton of time to improving scaffolding for this forecasting tournament.
That’s why I ran an experiment.
Experiment: Research Scaffolding for Forecasting Bots
One of the interesting findings from my previous experiment on model choice was that the different web search bots appeared to return a significant number of unique, relevant forecasting facts. This suggests an obvious scaffolding improvement: if you want good research for your forecaster bot, maybe you should run multiple researchers in parallel and combine them together into a single forecast. You might expect that this would reduce hallucinations (because the independent researchers are unlikely to tell the same lies) and improve forecasting (because they unearth more information). But this is just a theory, so I’d like to test it.
I tested a couple different hypotheses:
Adding multiple researchers would make it less likely for a forecast to include a complete hallucination.
Adding multiple different models would source additional information, resulting in a more accurate forecast.
Having a complicated architecture where roles are split up (e.g., web search, research context, forecasting) would allow for a more optimal forecast than just running everything through a single model call, because it allows each piece to be optimized for that one thing.
The approach I used for this was to test different configurations of the research component of my overall forecasting bot. For context, this is the architecture of my current bot:
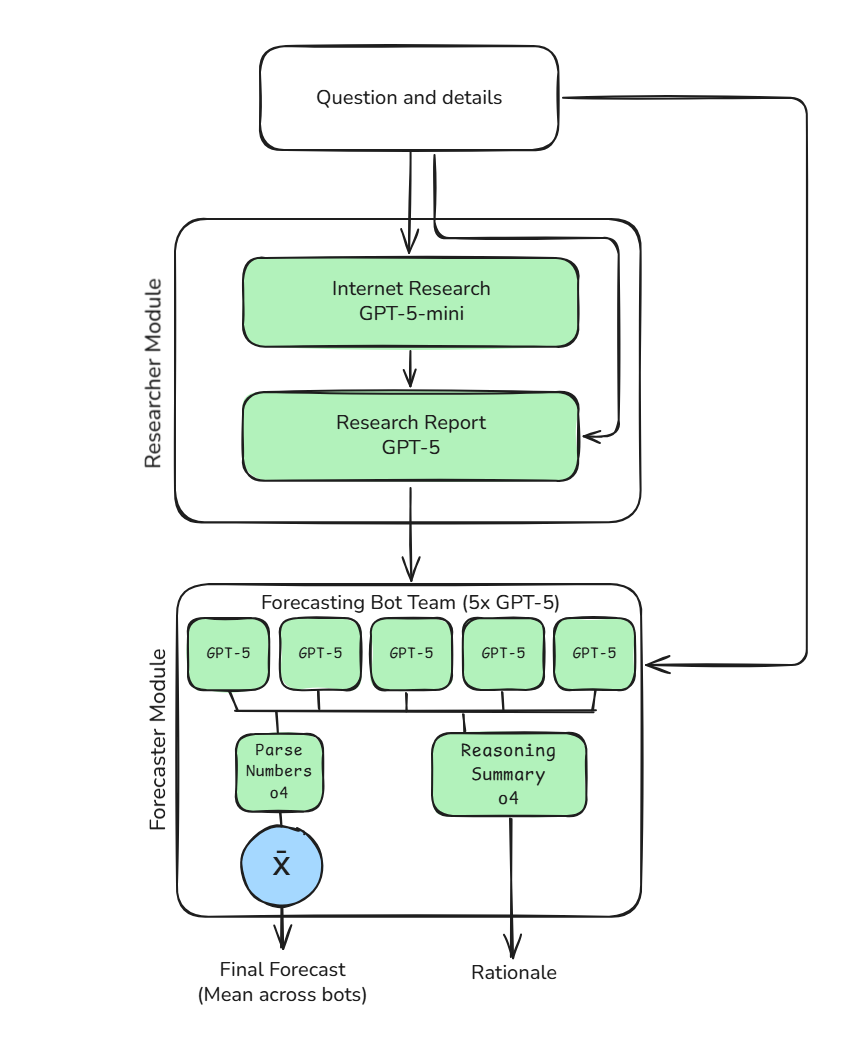
I created 5 variations on this bot approach to test against one another. Three of these were variations on my current architecture, and two were straightforward end-to-end bots where a single model runs the entire forecasting approach in a single query. The specific configurations were:
GPT-5-mini x1: Single researcher bot identical to my current architecture.
GPT-5-mini x3: Same approach, but the web search is run 3 times before being aggregated by the researcher.
GPT-5-mini + Claude Haiku 4.5 + Gemini Flash 2.5: Same approach, but now the 3 web searches are performed by different models running the same prompt.
GPT-5-mini end-to-end: This discards all scaffolding, and just runs the entire question through a single 5-mini model with web search enabled.
GPT-5.1 end-to-end: For comparison, I also ran this end-to-end approach using the most up to date OpenAI model, with medium thinking depth and web search enabled.
I also ran versions 1-3 with either no aggregation (just a single forecaster), or with aggregation across 5 independent forecasters using the same research (identical to the schematic above). For all of these experiments I randomly selected 30 Metaculus questions with at least 40 human forecasts and expiring within the next year. Many questions are essentially resolved already (with probabilities very close to 0 or 1), so I required that at least 10 of these questions had probabilities between 10% and 90% to capture more uncertain questions. Each of these questions was run through every bot configuration.
Measurement
Rather than manually grading each individual question for all these bot configurations, which would quickly grow pretty labor intensive, I instead compared the output of each to the human forecaster generated community predictions on Metaculus. I compared these using both brier score and Kullback–Leibler (KL) divergence, assuming that the community prediction was the true probability. Both give estimates of how similar the bot prediction is to the community prediction, and they ended up returning comparable results so I’ll mostly report KL divergence below.
The community predictions generally perform quite well, so comparing to this prediction is a good way to get a rough estimate of bot quality without waiting months for the questions to resolve. A KL divergence of 0 would mean that the bot was making identical predictions to the human forecasters, while a divergence of 0.05-0.20 is a meaningful disagreement and >0.5 is strong disagreement.
Using this approach does create a potential issue if the bots were actually better than the humans, because being better requires that they not make identical predictions. However, I feel relatively confident that this bot configuration is not generally superhuman. So, we can generally interpret these results as the model closest to 0 being the best performing model.
Results
Hallucination Rates
I’ve largely been focusing on error reduction from fact checking, so the first thing to do was test the hypothesis that including multiple independent researchers would result in fewer outright hallucinations. In this case I identified hallucinations as cases where the KL divergence was >0.5 (which corresponds with an ‘strong’ divergence).
Across all models there were a total of 5 cases where the bot diverged strongly from the community prediction. The breakdown of error rates was:
5-mini x1: 3 errors - questions [17102, 17104, 28371]
5-mini x3: 3 errors - questions [17102, 17104, 28371]
5-mini + Haiku + Flash: 3 errors - questions [17102, 17104, 28371]
5-mini e2e: 2 errors - questions [17102, 39336]
5.1 e2e: 1 error - questions [17102]
I was somewhat surprised to find that the inclusion of multiple researcher bots did not affect the error rate at all. All 3 of the bots using the more complex architecture made identical mistakes on the same 3 questions, and the straightforward end-to-end bots made fewer errors.
I reviewed each of these error questions individually and found that they generally did not represent true ‘hallucination’ of facts so much as a failure to understand the way Metaculus works. In particular the one question where all the bots made a mistake was very understandable.1 I end up excluding this question from the rest of the analysis since it is a clear outlier across every model and massively increases the overall variance.
This is a tiny sample size, but does suggest that simply throwing more researchers at the problem is not sufficient to have a big impact on error rate. For the first question of using a simple scaffolding approach to reduce hallucination, I think this counts as a null result that can rule out this approach having a major impact.
Accuracy Improvements from Scaffolding
The next question was whether this general scaffolding approach was adding anything in terms of overall accuracy. There are two pieces to this. The first is whether, as was suggested by my fact checking experiment, having multiple independent researchers would turn up additional facts that end up improving performance. The second is whether aggregating multiple forecasts together improves the performance over just running the model a single time.
For this piece I compared only the 3 variations of bots using the same general architecture with various amounts of scaffolding. Comparing across all questions the difference across scaffolding approaches was essentially nil:
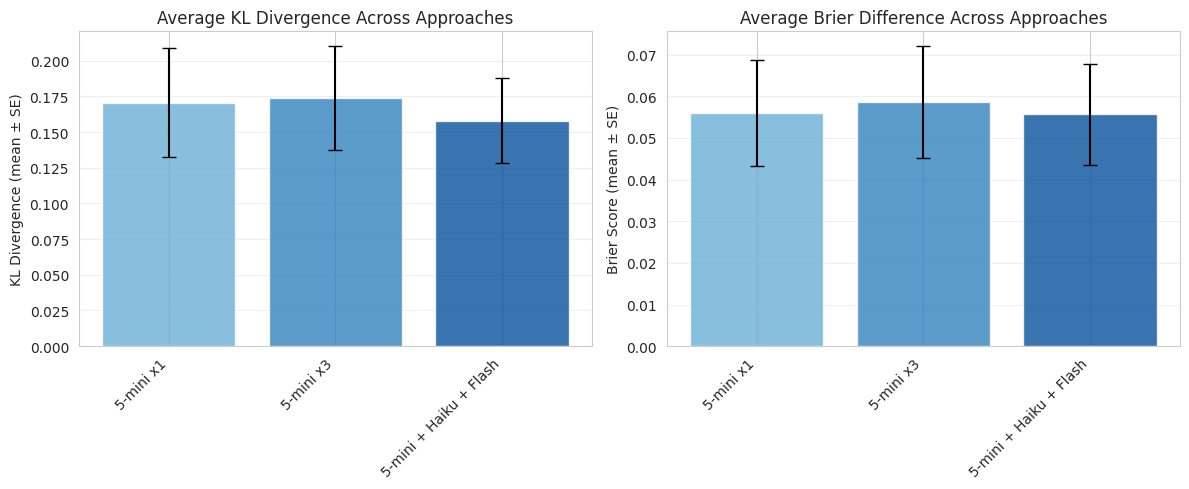
There may be some trend towards the more complex research architectures having better performance, but this is not even close to statistically significant (p = 0.9, 1-way ANOVA). This essentially rules out the hypothesis that this multi-researcher approach has anything to offer in terms of performance gains. If there is a gain, it is too small to justify the added cost of running 3x as many web searches.
The other piece of architecture was the aggregation of multiple forecasts together. To test this I compared the performance of the individual forecasts against a forecast aggregated across 5 predictions (mean). By construction it’s guaranteed for this to offer an improvement, but is this improvement meaningful?
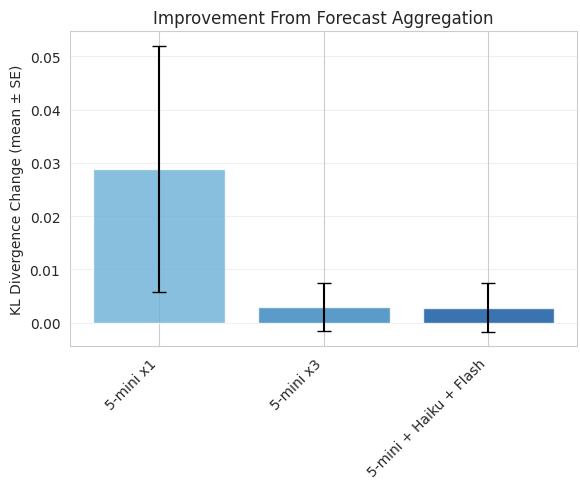
Answer: not really. There is technically a significant improvement from aggregation for the single researcher, but these improvements are tiny and are indistinguishable from 0 for the two more complicated architectures.
Together these results suggest that, at least for the specific scaffolding manipulations I decided to test, there was no clear benefit to running multiple researcher models and aggregating those predictions across multiple forecasters. Of the two manipulations, the aggregation approach does seem to offer a marginal benefit in some circumstances, but this benefit is pretty small. It’s possible that running this experiment with a much larger sample size would turn up a small statistically significant improvement, but we can rule out any major differences.
Complex Scaffolding vs. End-to-end Model
Those first two analyses suggest that marginal changes to the complexity of the scaffolding, adding multiple researchers and aggregating across multiple forecasters, result in no detectable change in the overall accuracy or hallucination rate. But does that mean that this scaffolding is generally useless?
I tested this possibility by including a version of the same underlying model (GPT-5-mini) that was run end-to-end performing the entire forecasting process in a single prompt. This collapses the entire architecture into just a single model call with web search enabled. So, literally, this is the entire ‘architecture’:
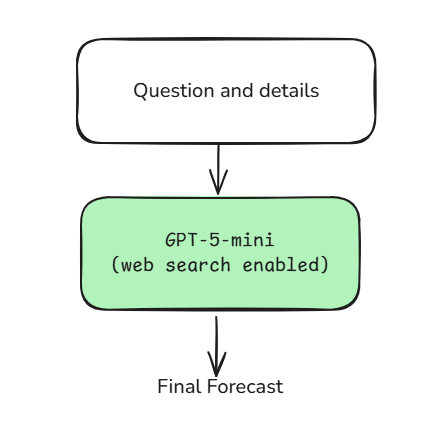
So how does my complicated architecture compare to just letting it rip with a single model call? Do we get any improvement from all this complicated coding work? Well…
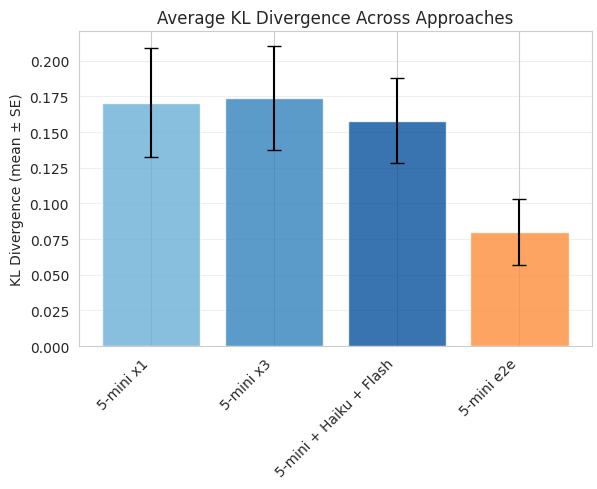
Here I’m comparing the complete, complex architecture with 3 different research approaches and aggregation included against a single 5-mini model call with web search. Not only does the single model call match the more complicated architecture, it’s actually performing significantly better. At least in this experiment the best ‘architecture improvement’ was just removing the architecture completely and letting the model do everything internally.
Technically, I also tested the architecture improvement of ‘just use a more expensive model’. So how did that work?
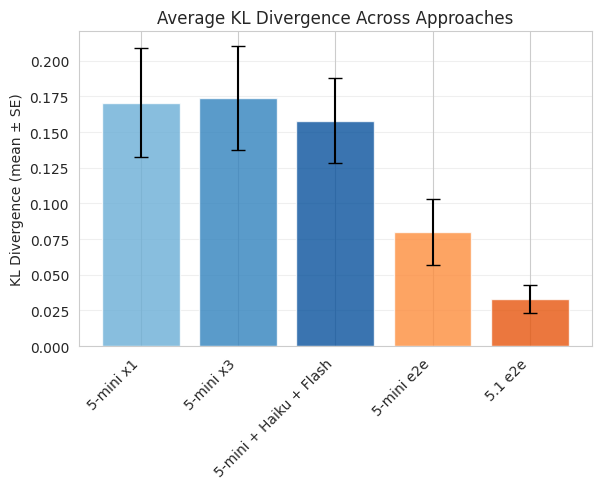
Yeah. GPT-5.1 was released last week, and when I started this experiment on Monday it was the newest model (Gemini 3, Grok 4.1, and GPT 5.1 Pro have all since been released - Things Move Fast). It turns out that just loading in the best model you have access to and letting it rip is by far the best approach here. Not only was it hard to even detect the improvements from the various scaffolding approaches I tried against one another, the end-to-end single model call approaches just blew all of them out of the water.
Conclusion
Reviewing the hypotheses I set out to test, I think we have relatively conclusive answers:
Does adding multiple research bots reduce hallucination rate
Tentative no, but low sample size.
Do multiple researchers or aggregation across forecasters improve accuracy?
Multiple researchers - Rule out substantial improvement.
Forecaster aggregation - Potential marginal improvement.
Does a complicated multi-step architecture improve performance over a single end-to-end model call?
A single end-to-end model call is far stronger.
Despite the null results, I think this experiment was worth running for two reasons:
This validated my suspicion that squeezing performance out of scaffolding improvements is challenging and low-ROI.
This experiment does not at all prove that scaffolding is useless. I set this experiment up to explicitly test a pretty obvious set of scaffolding improvements that scaled in a straightforward way, under the hypothesis that increasing scaffolding directly led to better performance. I think this hypothesis can be soundly rejected, but that doesn’t mean that there is no scaffolding that would be beneficial. It just means that this relationship is not straightforward, and that specific scaffolding choices need to be carefully made to have a potential impact.
It does demonstrate that going wrong in these scaffolding choices can have serious negative impacts on performance. So tread carefully.
Frontier models are becoming intrinsically very good at forecasting.
The biggest surprise to me was just how much more effective running everything through a single model call has become. GPT-5.1 had an average KL divergence of ~0.03 and a brier score difference of ~0.01. This can be interpreted as nearly indistinguishable from the community prediction, which is made up of dozens of human forecasters. These community predictions are generally at the very top, performance wise, and often beat all but a few individuals in any given tournament. Being very close to these predictions implies that bots may already be approaching even the best forecasters.
There are a couple reasons I can think of for this: the models themselves are getting smarter, they can handle more context, and agentic web search is incredibly useful for this task.
When models couldn’t handle a massive chunk of context, it made sense to split up the forecasting process into multiple discrete pieces so as not to overload any individual piece. That doesn’t seem to be the case anymore, and without that limitation it’s helpful for the model to be able to think about both the forecasting and research pieces in parallel. Especially with agentic search, where the model can ask questions and look things up as it works through the problem, allowing the model maximum flexibility seems like the optimal strategy.
In manually reviewing the research and forecasting pieces of these different bot approaches, I was frankly blown away by the quality of GPT-5.1 running end to end. The ability to consider the question, make a research plan, search the web to find the answers to those research questions, and synthesize that all into a coherent forecast was extremely impressive. I am not an expert forecaster, but I felt like these reports were far stronger than I would achieve on my own even with several hours of work.
I’m not sure when AI forecasting will officially beat expert humans out of the box, but I feel like they are already superhuman if the human in question is me.
In this question, every bot considered that “Framework for Artificial Intelligence Diffusion” Interim Final Rule (IFR) published by the Commerce Department’s Bureau of Industry and Security (BIS) on January 13, 2025 should count as satisfying the criteria that ‘export restrictions on AI software are implemented’. In May this rule was rescinded, but the models interpret this as counting because the rule was ‘implemented’ at some point prior to 2026. Clearly, the Metaculus community disagrees that this counts. That rule specifically refers to model weights, which arguably don’t count as software on their own. It’s also certainly arguable that, because the rule was never enforced, it doesn’t count as implemented.
I have some sympathy for the model’s views here. This doesn’t seem like a hallucination as much as it seems to be lacking context about how Metaculus questions are operationalized. An important piece of context they seem to miss is: if that particular rule counted for purposes of question resolution, the question would already be resolved. This could in principle be avoided with scaffolding, but it would be different from what I’ve implemented here.