
Better AI Fact Finding Through Model Choice
A Model Comparison Experiment (Fact Finding Experiment #1)

The thesis behind my bot development for this season has been that the reasoning is generally fine, but that the major weakness of AI forecasters is their propensity to hallucinate facts. It doesn’t matter how smart your AI is, or how fancy you get with converting that intelligence into predictions, if a critical ‘fact’ feeding into that forecast does not match reality you will perform poorly.
In a previous post I discussed a few strategies that seemed immediately applicable to forecasting: model selection, prompt engineering, and scaffolding. Today’s post is focused entirely on the first of these.
What follows is a nearly manuscript length description of the experiments I ran and their results. If you are interested in the details, they are all there. If you are less interested in the details, the key takeaways were:
Using native search (often, agentic search) is very strong for sourcing relevant information.
GPT-5, GPT-5 mini, and Sonnet 4.5 models generally performed the best in my tests, especially with agentic search.
Independent searches, even with the same prompt, generated a ton of unique information. It is likely beneficial to run more than one search and aggregate them, rather than relying on a single model.
There was a small improvement in truthfulness when multiple models reported the same fact, but this seemed to be fairly modest.
Objective: Report (Real) Facts
One of the primary advantages AI forecasting bots could plausibly have over human forecasters is the ability to process vast amounts of information very quickly. This is only useful if that information is relevant, and if it faithfully makes its way through the information gathering process and into the forecast.
The goal, then, is to test the ability of various models and approaches in sourcing this information. There are two critical criteria for whether a model succeeds or fails at this task.
The information must be true.
The information must be complete.
The first is obvious, as erroneous information can be disastrous for models that often lack context (i.e., common sense) to do their own fact checking. For the second, missing a key piece of information (such as, whether a certain candidate has dropped out of the race) is nearly as bad as it can lead to placing high probability on events that are actually impossible.
The gold standard for measuring these two factors would be to have human experts generate labeled data to compare against the bot generated responses. Unfortunately, these data are incredibly time consuming to generate, and not really worth doing for this simple experiment.
There are some pre-existing datasets that generally get at this idea, but none which are an ideal fit for the types of open ended, time sensitive questions that are asked in a forecasting tournament.
Instead, I took a couple different approaches relying as much as possible on automated grading using LLMs to evaluate the model responses, largely inspired by this paper. There are some concerns of the circularity of this all (having LLMs grade LLMs, when they have the same issues), so I also incorporated some human (me) checking. Still, I think this automated approach has some value for helping us decide which models to use and found it generally agreed with my own impressions.
Experiment Setup
The basic experiment structure was:
I pulled 5 forecasting questions from both the main AI benchmarking tournament and the most recent minibench (10 primary questions total).
For each forecasting question, 5 fact-based sub-questions were automatically generated by Claude Sonnet 4.5 to give each researcher model a common set of questions to answer (50 sub-questions total).
These questions were fed into each of 11 different models, which were given the same prompt instructing them to answer the 5 sub questions with clear, factual answers of 1-3 sentences each.
For a subset of 5 models, I tested with two different variations1 on web search bringing the total number of evaluations up to 16.
The reports generated by each of these model researchers were the basis of the following experiments, which all did something a little different with them.
Consensus Among Models
The first experiment leans heavily on the idea that models, when they hallucinate, are unlikely to have the same hallucination as other models.
To measure this, I set up a group of 3 ‘judge’ LLMs (Sonnet 4.5, Gemini Flash 2.5, and GPT-5 mini). Each judge was tasked with reading all of the researcher model’s responses to the individual sub-questions, identifying the consensus view across models, and then labeling each individual model response as either agreeing with or disagreeing with that consensus.
I expected that the models with the highest hallucination rate would have the lowest agreement with the group consensus, as the hallucinations should push them away from this common line of thinking.
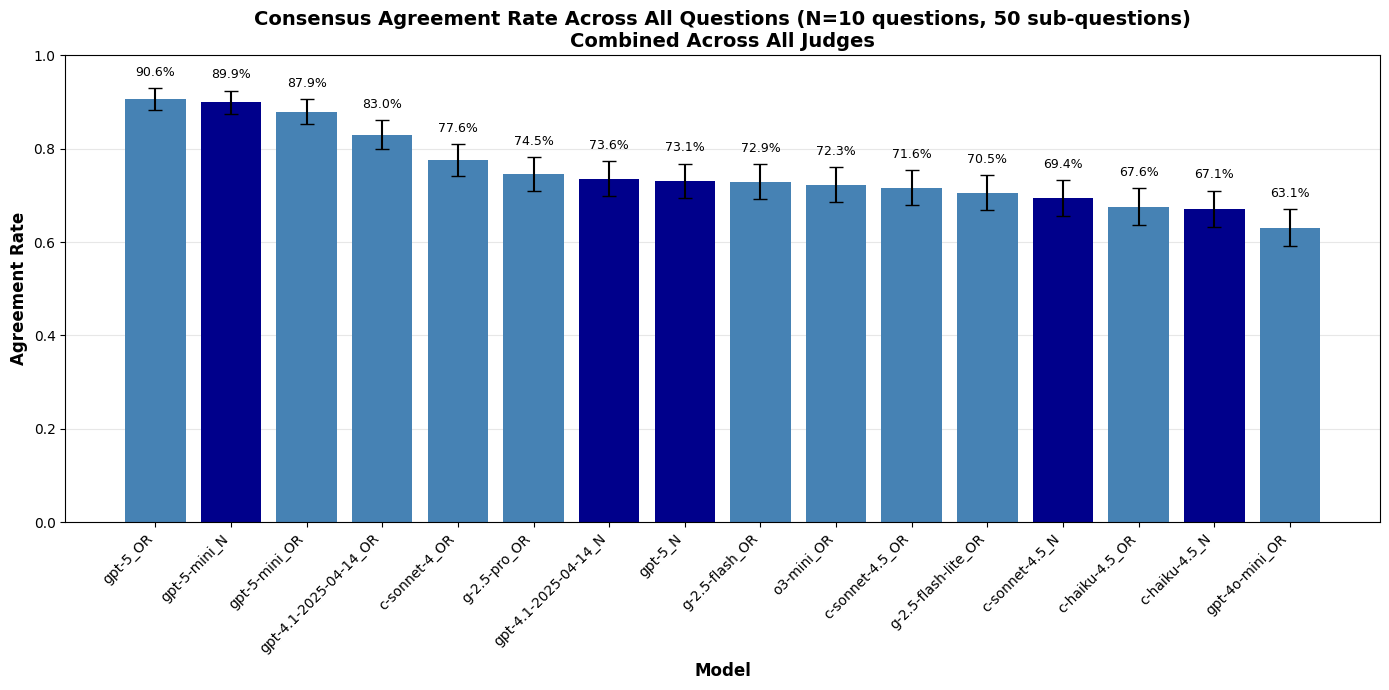
In this plot I’m showing the rate at which each model was judged to agree with the consensus view across all sub questions and all judges (so, effectively 150 data points per model). The darker blue indicates models using their own native search utility, rather than the built in OpenRouter Exa search.
Consensus was highest among the GPT models, particularly GPT-5 (standard or mini). I included GPT-4o specifically because I noticed in the past that it very frequently hallucinated facts, so it is reassuring to see it bringing up the rear. I also included some older model versions within the same families, and generally the newer versions seem to agree with consensus more than the older versions.
One interesting note is that, in all cases except GPT-5-mini, the native search options generally have lower agreement than the corresponding OpenRouter versions. This may be because they are able to use agentic search which would cause them to discover a different set of facts, while all OpenRouter searches are likely to be very similar as they all rely on Exa.
This brings up an interesting point, which is that it may not necessarily be bad for a model to disagree with the consensus. In some cases, this disagreement will be due to hallucination, while in others it could be because the researcher discovered true information separate from that included in the consensus.
Completeness of Research
The consensus view is one way to avoid hallucinations, but it runs the risk of incorrectly deleting true facts simply because the majority of researchers missed them. So I’d like to know something about those facts before deciding a model is performing poorly.
To address this, I used an LLM (Sonnet 4.5) to parse through each model response and pull out a list of individual facts contained in the response. It then went through these facts and labeled them as either unique (meaning no other model reported an identical or similar fact), or shared (at least 2 models reported the same fact).
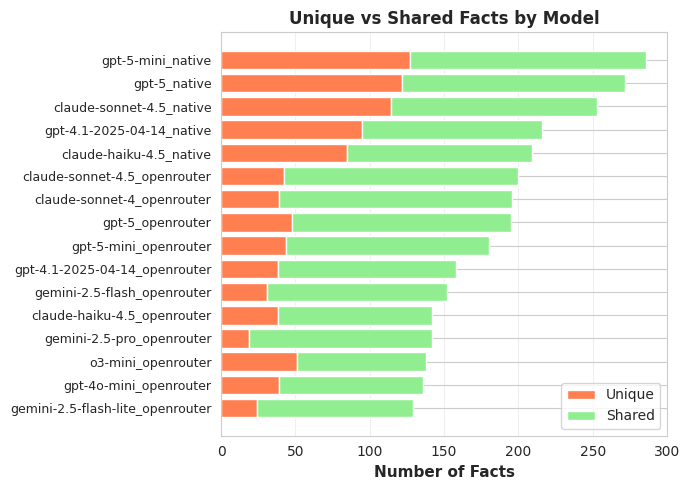
Here I’m showing the total number of independent facts generated by each of the research models across the 50 sub questions.
The most obvious takeaway from this is that the native search option generates a much higher proportion of unique facts (as well as more facts overall) than using the OpenRouter search. This verifies my suspicion from the previous experiment that the agentic search is turning up a lot more information. It is also likely why those models came out as generally less agreeable.
Beyond this, there aren’t clear trends among the models using OpenRouter search. GPT-4o (the liar bot) doesn’t seem to have a disproportionate fraction of unique vs. shared facts, and the number of facts reported seems to correlate more with model size than anything else. Also, despite all of these models receiving similar input information, they all seem to latch on to different pieces of that information to report unique facts.
Having more information is helpful for making accurate forecasts, but we would also like to know whether these facts are true before we go crazy adding as much information as possible. The consensus agreement from the first experiment goes some way towards answering this question. But, because native search seems to be both less agreeable and to generate more information, we really need to dive a bit deeper and evaluate whether this added information is accurate.
Fact Checking
This relatively small experiment still generated a ton of individual facts to verify. In total, from 50 test questions, there are around 1000 unique facts and 500 shared facts to check to evaluate model performance.
The gold standard would be to have several people manually verify each of these facts. But, this is an experiment I’m running on my own and posting on a blog for free… So, as a compromise, I took 50 randomly selected questions (half unique and half shared) and went through them myself to get a sense of how the unique vs. shared facts stacked up as well as how each model was performing when it identified something unique.
I categorized these questions into 4 groups: true, false, ambiguous, or irrelevant. Ambiguous facts were on the edge of true or false, or otherwise more open to interpretation. Irrelevant facts are technically facts but not ones that have any bearing on the question asked (things like, ‘the search results didn’t contain any information on this topic’).
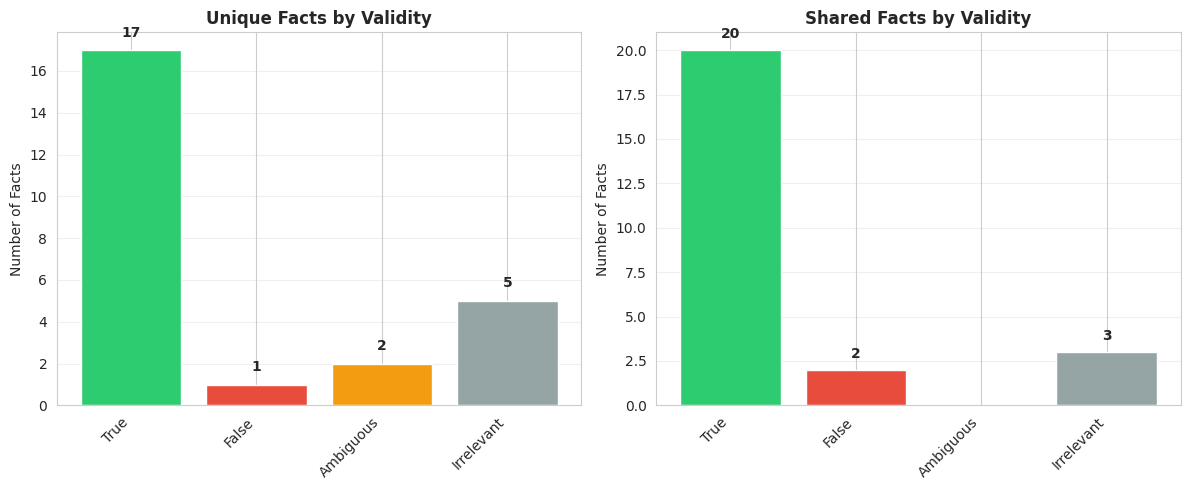
Admittedly, this is a tiny sample so it is hard to draw too many conclusions. But I was struck by the general strength of the unique answers. Before running this experiment, I would have thought the shared facts would generally be more likely to be correct. In this sample, only one of the facts was an outright hallucination (although I marked 2 as ambiguous), compared to 2 false facts in the shared facts category.
One issue with this analysis is that the strongest models produced more unique facts, which biases the evaluation towards stronger models. To compensate for this I graded another set of 80 randomly selected questions, this time picking 5 from each model.
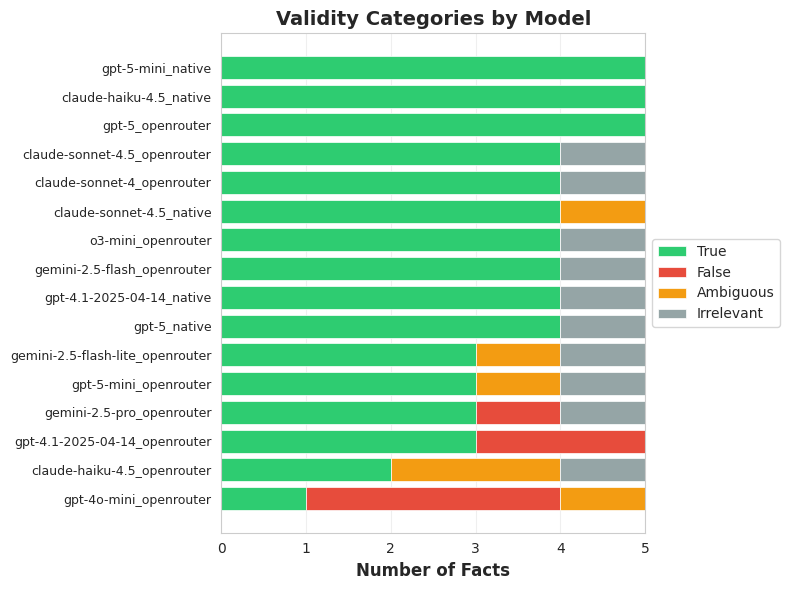
As expected, 4o was the worst offender in terms of flat out making things up. Beyond that there does not seem to be a clear trend among the models.
Again, this sample size is extremely small, which makes it hard to conclusively say anything based on these numbers. To address this problem, I went back to the LLM well and attempted to automatically grade the factuality of individual facts.
Automated vs. Human Labeling
There is some concern about the circularity of having an LLM grade the factuality of another LLM’s outputs. Fortunately these models do somewhat better when given a single fact and asked whether it is true or false (this is basically the approach used my methods like SAFE). So, my approach here was to sample facts individually and check them one at a time with independent search queries. I then compared the model results to my own ‘gold-standard’ of manually looking things up, with the hope that the model can roughly recreate my own findings.
Because I wanted to run this on hundreds of facts (meaning hundreds of queries), I went with Gemini Flash 2.5 with OpenRouter Exa search as the evaluator model since it was the most time/cost effective. This is likely sub-optimal from a pure accuracy perspective, but hey feel free to sponsor me to run this again with more expensive models.
After some initial experimentation, I ended up excluding anything I labeled as “irrelevant” from this entire analysis. When given the option, Flash 2.5 was very prone to labeling things as irrelevant, which reduced the effective sample size dramatically without reducing the cost or time required. So here the model is answering only with true, false, or ambiguous if it was unable to determine whether the claim was true or not.
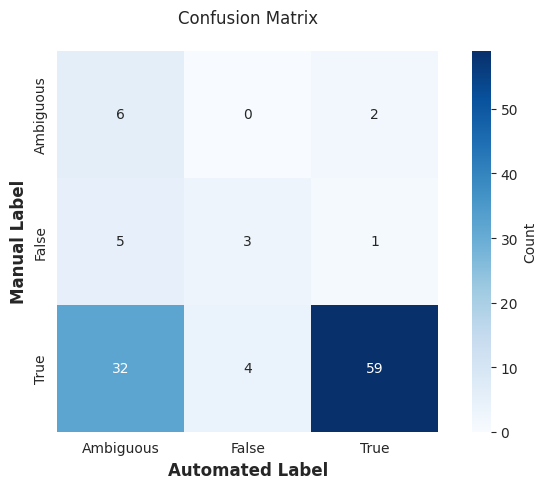
In this confusion matrix I’m comparing the labels generated by the model to my own manually coded responses. A perfect result would have all the numbers running along the diagonal as this would indicate perfect agreement. While the model seems to agree with me fairly often (particularly when the answer is true), there are a substantial amount of disagreements.
The main source of disagreement appears to be that the model is far more likely to label something ‘ambiguous’. This can be seen a little more clearly in this next plot, where cases when the model says a fact is ambiguous are marked in yellow.
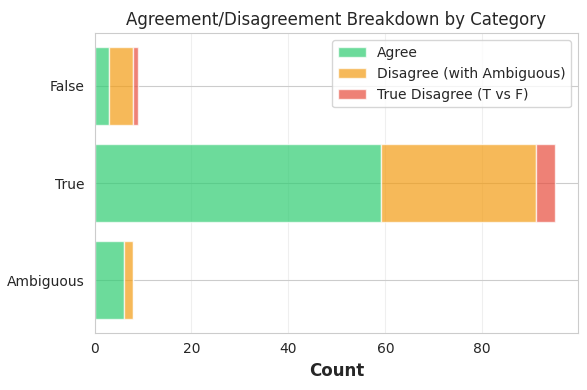
The model does an ok job of capturing my own findings when ignoring the ambiguous cases. The majority of my true judgements were verified with the model. There were 4 instances where I labeled something as true and the model labeled it false, and only one instance of the reverse.
The overall agreement between my own and the model’s ratings was only around 65% (roughly comparable with more advanced methods like SAFE), but almost all of this was in the model labeling things ambiguous when I was able to come to a more clear determination. I tentatively interpret this as having the true/false answers be useful, while ambiguous labels provide little information in either direction. In the next analysis, I’ll be eliminating those ambiguous labels and only looking at facts the model labeled as true or false.
Automated Fact Checking
Using this approach as a rough proxy for my own labeling, I can rerun the fact checking experiment with a larger sample size. I took the same 130 facts I manually judged, plus another 200 randomly selected facts. I then de-duplicated this list, as well as removed all the questions that the model labeled ‘ambiguous’, resulting in a total of 194 questions.
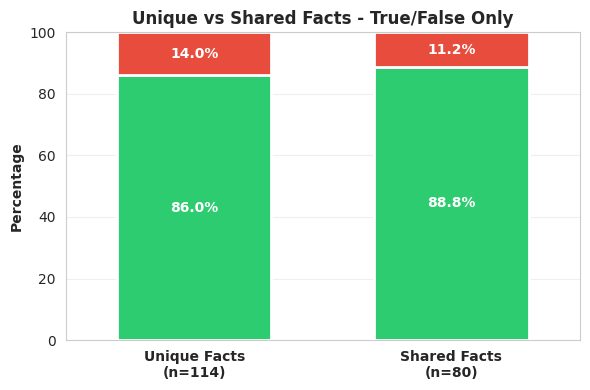
First, I compared the unique facts to those shared across multiple models. There did appear to be some benefit of having multiple models report the same fact, in terms of accuracy, but this benefit was surprisingly small. This meshes with what I found in the manual labeling analysis, and suggests there isn’t too much gain to be had (in terms of accuracy) by checking the facts against other model outputs to identify hallucination.
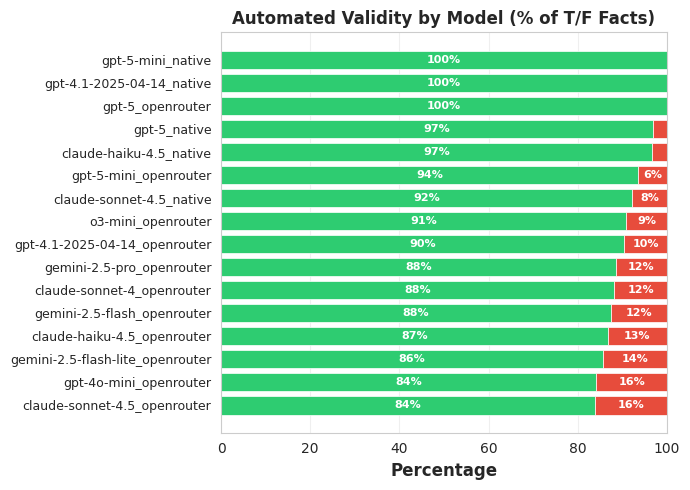
I also repeated the evaluation of accuracy across each model. This generally agrees with the ordering I found in my manual checks, though the agreement is far from perfect. The most surprising thing here is that Sonnet 4.5 with OpenRouter search ends up so low, even worse than 4o.
I would take these automated judgments with a big helping of salt when evaluating the models. But, at a high level at least, they seem to agree with the findings from the manual version of this experiment.
Summary
This started with what I assumed would be a simple question: Which model makes up the fewest lies? Ultimately it turned into this monstrosity of analyses, only to find that the instinctual answer I had at the beginning (newer models are better) is basically true. Still, there were a few interesting things that came out of these experiments.
The native, agentic web search is far more powerful than using the default web search provided by OpenRouter via Exa. This was true both for factuality and completeness of information.
There are free credits provided for this tournament via OpenRouter, but these are not eligible for web search. So, if you want to get this benefit, the only route right now is to make (and pay for) your own OpenAI/Anthropic API keys.
I did not test AskNews, which many people are currently using in this tournament, as an alternative to searching the web directly. It’s possible that this provides similar benefits, but I still suspect that agentic search is the way to go.
Across all of the experiments I ran, GPT-5 (either standard or mini) and Sonnet 4.5 repeatedly came out on top. There was some concern that these larger models would be more likely to hallucinate, as they typically underperform smaller models on hallucination benchmarks. But, at least in this fact gathering context, I didn’t see any evidence of that. I suspect this is because hallucination benchmarks often test on intentionally inserted nonsense facts, as opposed to real world data.
The number of unique facts generated across different models was pretty surprising to me, especially since some of the models I tested are just smaller versions of the frontier models. This suggests there’s some benefit to having multiple fact gathering models run independently, and then aggregating these facts together.
Relatedly, there was a small benefit in truthfulness from checking to see whether multiple models reported the same fact. However, this benefit was fairly small. Certainly I would not discount a fact simply because it was reported by only a single model (though if two models explicitly disagree that may be another story).
In the future I hope to return to this topic and explore the other two pieces of hallucination reduction for bot researchers: prompt engineering and scaffolding. So don’t forget to subscribe for more manuscript length, incredibly niche investigations into AI forecasting.
A note on web search
Many people participating in this tournament are using AskNews for their web search needs. This seems like a great service, but getting API access (beyond the free credits provided for the tournament, which I quickly exhausted) runs around $250-1000/mo. I couldn’t justify this for a hobby project.
I originally intended to compare all models using a service called OpenRouter, which uses the same API to call multiple models. However, in initial experiments I found that some models were using dramatically more tokens (>30x) for web search than others.
It turns out that OpenRouter sometimes routes web searches through the native web search client, and if that is not available instead uses a separate service called Exa which searches a predefined number of web pages and returns a brief report. Unfortunately, even when native search is available on OpenRouter it appears that searches are sometimes unpredictably routed through this Exa approach.
The native search option is generally far more comprehensive, as it allows the model to agentically search by trying multiple different variations until it finds what it’s looking for. To provide a more fair comparison across models with and without this feature, I ran all models with the default OpenRouter Exa search. I then ran a subset of the 5 models I was most interested in through their own API with native search enabled. This allows comparison across models with the same search data (OpenRouter), as well as an idea of how much benefit can be had by allowing agentic search.