
User Says: Please Don’t Make Things Up
Towards Reduced Hallucination in AI Forecasting

One of the most fundamental issues with getting LLM-based AI to deliver on its promise to revolutionize everything about everything is that sometimes the models just make things up. The term of art for this is ‘hallucination’, and almost anyone who has used ChatGPT or other consumer facing LLMs has experienced this at one point or another. There’s even an online cottage industry of sharing particularly funny examples of AI failure.
It’s an open debate whether hallucination can be eliminated or whether they reflect an insurmountable barrier inherent to any LLM based AI approach. Fundamentally, LLMs are trained to predict the string of words that follow a different string of words. This is an intrinsically probabilistic process, and it’s possible that this randomness can never be truly eliminated. However, human brains are also probabilistic, and we nevertheless seem to be able to function pretty well [citation needed]. Hopefully, we can implement some approaches to at least achieve the level of factual correctness and truthfulness that are standard in human thinking.
In AI forecasting in particular there is clear damage from hallucination that can be far more impactful than subtle issues in reasoning. In my last post I talked about an example where my forecasting bot incorrectly reported a number from the internet and as a consequence made a wildly bad prediction. Much like in real life, being very wrong in forecasting tournaments is much worse than being just a little wrong, and this one hallucination effectively wiped out the gains from 16 other modestly correct predictions. Imagine a similar issue happening when AI systems need to make important decisions where the consequences aren’t as easy to shake off (like knowing if weapons of mass destruction are being developed under Saddam Hussein) and we have all the motivation we need to try and solve this problem.
Fortunately, people a lot smarter than me have been working on reducing hallucination. This post explores some of what they’ve been able to accomplish and how this can be incorporated in AI forecasting tools.
Choose the Best Model
The most straightforward and effective approach in most applications is simply to use a better model. The bitter lesson of AI advancement is that, compared to clever tricks or targeted optimization, just scaling up computation and data quantity has proven more effective at basically every task. From our perspective this means we are almost always better off using the best models developed by leading edge frontier labs than trying to do anything fancy with fine tuning or training our own models.
But which model to pick? Over the last couple of years, leading models have become almost commoditized. At least among the leading 3-4 labs, there is no clearly dominant company and the ‘top’ model typically holds the crown for a few weeks to a couple months at most. This means that it’s challenging to simply intuit which model will be the best performer. On the one hand, as long as you stay within the narrowly defined current generation of models, you are unlikely to do too poorly on this. On the other hand, if we care a lot about accuracy, we’d like to have some way to pick the absolute best option. Benchmarks are one way that we can quantitatively make this decision.
Benchmarks frequently cycle in and out of popularity, but one relatively high profile benchmark for hallucination specifically is Vectara which compares hallucination rates within a RAG framework. I’ll talk about RAG a bit more later in this post, but the important thing to know for now is that it’s something of an ideal case for avoiding hallucination. So, the numbers you see on this plot are going to be, in absolute terms, much lower rates of hallucination than you will likely see in the wild. Nevertheless they should provide a good relative benchmark when picking across models. So which models make the fewest things up?
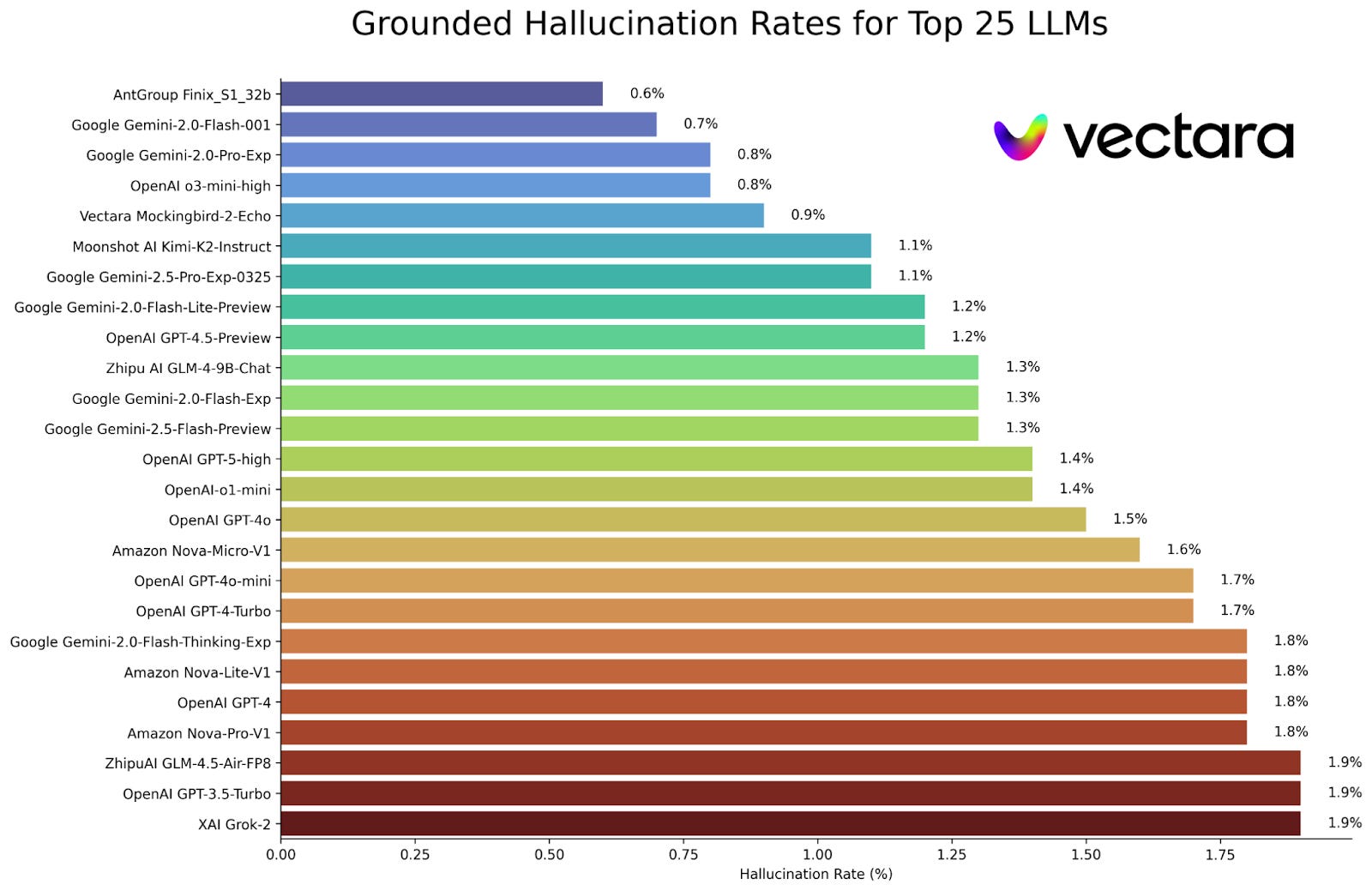
Of the major models, Gemini or GPT o3 seem to be potentially good choices, while Grok 2 rounds out the top 25 (interestingly Grok 4, the most current version of the so called “truth seeking” AI, is ranked 98th). It’s worth clicking through to the full leaderboard to see where your models might end up, as some of the findings are surprising. For instance, while GPT-5-high performs much better than GPT-5-mini (not shown because it’s outside the top 25), the opposite is true for o1-mini which performs better than regular o1. While it’s good to take benchmarks with a massive grain of salt, this does undermine the idea that you can simply use the best/most expensive model you have access to and get the best performance (at least when considering this issue of non-hallucination).
There are some big caveats to using these benchmarks to pick your model. First, because it’s a RAG system, this doesn’t reflect the hallucination rate you might care about. For my model, I care most about hallucinations when summarizing web search results, so RAG based benchmarks are probably relatively safe. Second, benchmarks often disagree with one another. A clear example of this is seeing GPT-5-high barely outperforming GPT-4o in Vectara, while in their own press release OpenAI reported that GPT-5 had 45% fewer such errors than 4o. Lastly, public benchmarks can be gamed, so you should have at least some skepticism when interpreting standings. In general, the simplest approach may be picking models that seem generally capable but double checking benchmarks to make sure you aren’t ending up with one of those that perform inexplicably poorly. Beyond that, explicitly testing several models in your specific pipeline is worth doing, as there is a ton of variability both across benchmarks and across contexts.
Prompting Improvement
Prompt engineering is a surprisingly impactful way of manipulating models without requiring computationally expensive fine tuning or retraining approaches. I hope to have a more complete investigation into various prompting approaches at some point, but in the meantime I will write a bit about approaches that seem particularly relevant in this context of minimizing hallucination. The categories below progress roughly from simplest to most complex, though each category should be considered very broad as they hide a significant amount of variance in terms of specific approaches.
Zero-shot, One-shot, and Few-shot
The most straightforward approach to improving hallucination is simply to improve the detail and specificity requested in the prompt. This was particularly noticeable in earlier versions of LLMs which had fewer built in system level prompts to control the tone and style of responses. In my experience this is less critical in most leading edge models, which seem able to translate ambiguous prompts into relatively well structured responses fairly reliably. However, there is still substantial difference in quality between a prompt that looks like this:
“Provide a summary of news relating to [question]”
Compared to something like this:
“Provide a summary of news relating to [question]. This summary should focus on the most recent and relevant news, and priority should be given to authoritative sources (e.g., respected news organizations, institutional publications, and government provided data). Importantly, if there is evidence that the question will resolve imminently that evidence should be emphasized in the report.”
While there are some empirical papers looking at the impact of this type of prompt design on various aspects of model performance, this type of engineering is still far more art than science. There are some attempts at regularizing this, such as iteratively changing the prompt in a loop to achieve improvement in your desired metric, but even these approaches are very fragile. Often, a prompt that works great for one model will not work nearly as well in the next, even if it is just an updated model from the same company. Ultimately, it doesn’t seem like there are great alternatives to simply trying many different prompts and manually evaluating how well they achieve what you are trying to do.
The above prompt approach is sometimes referred to as ‘zero-shot’ prompting, which is contrasted with ‘one-shot’ or ‘few-shot’ prompts. In zero-shot, we simply tell the model what we want it to do but don’t provide any examples. If we want this to be more structured, we can instead provide the prompt above with something like this attached:
“Below is an example of the desired response:
Question: Will the US pass a federal bill on AI regulation before January 1, 2026?Imminent resolution: There is no evidence that a qualifying bill has passed or is certain to pass in the provided timeframe.
News summary: The Hill reports that the following potentially relevant bills are under consideration… but that none of them are expected to come to a vote before the end of the year”
Providing an example such as this helps guide the model to produce the type of analysis we are hoping to receive. One-shot prompts can be further strengthened by including multiple such examples, i.e., few-shot, ideally covering the range of responses that might be required. For example, you might extend the above example to include a case where the resolution appeared imminent. There is some fairly solid evidence that including this kind of structure in prompts can improve their quality, though I’m uncertain how necessary this is in the most up to date models.
Controlling the Thought Process
‘Chain of thought’ prompting was big news when it was first developed a few years back, though now it (or something similar) lives under the surface of essentially all reasoning models. In chain of thought, we explicitly prompt the model to ‘think step by step’ through the process rather than simply jumping to the answer. This helps because it seems to encourage the model to explicitly write out the multiple steps required to achieve the answer, which apparently reduces its tendency to just riff. While this initially provided significant gains in reasoning for different LLMs, my impression is that much of this value is already baked into most modern models which limits its value as a standard prompting strategy. There are, however, several adaptations to this approach which may be more narrowly useful in the context of hallucination reduction and improving forecasts more generally.
The first of these narrower approaches is question decomposition, where the model is asked to break the larger ask into smaller pieces before addressing those individually. In the context of prediction, this might look something like breaking the large question of ‘Will the US pass a federal bill on AI regulation before January 1, 2026’ into several smaller questions such as ‘how many days will congress be in session before January 1, 2026,’ and ‘are there any relevant bills under consideration’ and so forth. These questions are in principle easier to answer, which reduces the model’s tendency to just hallucinate the answers.
Another approach, self-consistency, instead attempts to control for hallucinations by aggregating across multiple different responses. To paraphrase Tolstoy, true statements are all alike, but hallucinations are all false in their own way. By asking a model (or several models) to answer the same question multiple times and then comparing their results, self-consistency expects that the true statements will agree with one another while any hallucinations will wash out. Empirically, this does seem to improve the quality of both reasoning and hallucinations. Unfortunately, there is no principled reason why hallucinations could not agree with one another (for example, multiple models could assume that congress is currently in session and miss the ongoing government shutdown) so this approach does not offer anything like a true guarantee of accuracy.
Internal Argument
One of the most intellectually appealing prompting approaches (at least if you’re a huge nerd like me) is a category broadly defined as ‘multi-agent debate.’ In its most basic form, this involves having more than one LLM approach a question from multiple perspectives and have a back-and-forth debate about the answer. This can be refined in many different ways, such as having the models take on different personalities, or using a third ‘judge’ model to arbitrate the disagreement. While this debate approach is often used to improve the quality or faithfulness of reasoning, it can also reduce hallucinations because fact checking your opponent is one way of undermining their argument and winning the debate. This is analogous to what human thinkers in an effective truth seeking team might do (for instance, in adversarial collaborations), and there is some fairly strong evidence that it improves accuracy in various contexts.
Unlike the other prompting approaches in this section, this one does require a little bit of scaffolding. While it’s possible to write a prompt asking a single model to generate multiple arguments, it works best to have multiple model calls. This requires proper handling of prompts, context, etc through multiple rounds of argument. While this is technically possible working through something like ChatGPT on your web browser, it’s much more convenient to implement programmatically. This approach straddles the boundary between pure prompting approaches and the more technical/structural approaches described in the next section.
Structural or Technical Solutions
Although they are not directly applicable to this forecasting tournament (outside some potentially well supported efforts), I wanted to briefly touch on a couple of the most popular and effective technical solutions for reducing hallucinations.
The first of these is Retrieval-Augmented Generation (RAG), which uses vector based search across a pre-existing database of information (think, court cases or a company’s internal documentation) and feeds that in as context when models are generating responses. This has proven to be very effective at making LLMs produce more reliable information in specific settings. Of course, this requires a fair bit of structural support, most important of which is to generate and maintain a vector embedded database containing all of the information you want to use as context. This is a bit problematic in the context of AI forecasting, which could conceivably deal with a huge range of topics and relies on information being constantly updated as news filters in. The challenge is not insurmountable, but does represent a significant amount of effort. My impression is that this is part of the approach in AskNews or various similar services for academic writing, which might be one way to get the benefits of RAG without needing to maintain your own curated and up to date news database.
A second popular approach is Reasoning + Act with tools (ReAct), which interleaves model reasoning steps with tool based action steps. The core idea here is that the model should seek out information when it is unsure, rather than simply hallucinating the answers. This approach has proven very effective both for reducing hallucinations and avoiding common pitfalls like making errors in structured areas like math. Implementing this kind of structure requires a significant amount of programming investment and testing, which then needs to be re-implemented and tested every time a new model is swapped in. With a strong team, this could likely produce some pretty impressive results in a forecasting bot. Without a strong team, it’s likely better to rely on thinking/reasoning models (which generally have a similar ability to use tools and multi-step reasoning) to get much of the benefit without as much overhead.
These are just two examples which really represent broad categories of technical solutions to hallucination. This rabbit hole runs very deep, and even these two examples split fractally into dozens of additional refinements. A deep dive into all these intricacies is well beyond what I have the capacity to get into in this post, but there is plenty of fertile ground to apply these or similar approaches to forecasting AI.
TLDR: Where to Take This for Forecasting Bots
The interest in reducing hallucinations generally is immense, and there is a correspondingly massive amount of research in this area of which this post barely scratches the surface. Condensing this down to a few key takeaways:
Use benchmarks (or, ideally, experiments) to pick the best bot for your purpose.
Keep in mind that the largest/newest/most expensive bot is not always the best, especially for the narrow task of minimizing hallucinations e.g., when summarizing news.
Improve your prompts using validated strategies.
Adding better zero- or one-shot prompts can have a significant impact without requiring a ton of effort, though this is more art than science.
More involved approaches like self-consistency or multi-agent debate also have some interesting potential, particularly for coming up with forecasts.
Look into concrete technical solutions (if you have the bandwidth on your team).
Things like RAG and ReAct are the most empirically well supported strategies, but they come with significant technical overhead which may not be realistic to implement.
I’m planning to experimentally test some of this advice in my own narrow context of accurate internet search for my own forecasting bot, and hope to have a post on that soon to follow-up. So stay tuned for that in the next week or two.
Love this take, the hallucination issue is a huge blocker for LLMs. Do you think we’ll ever truely get past this ‘probabilistic’ hurdle for good?